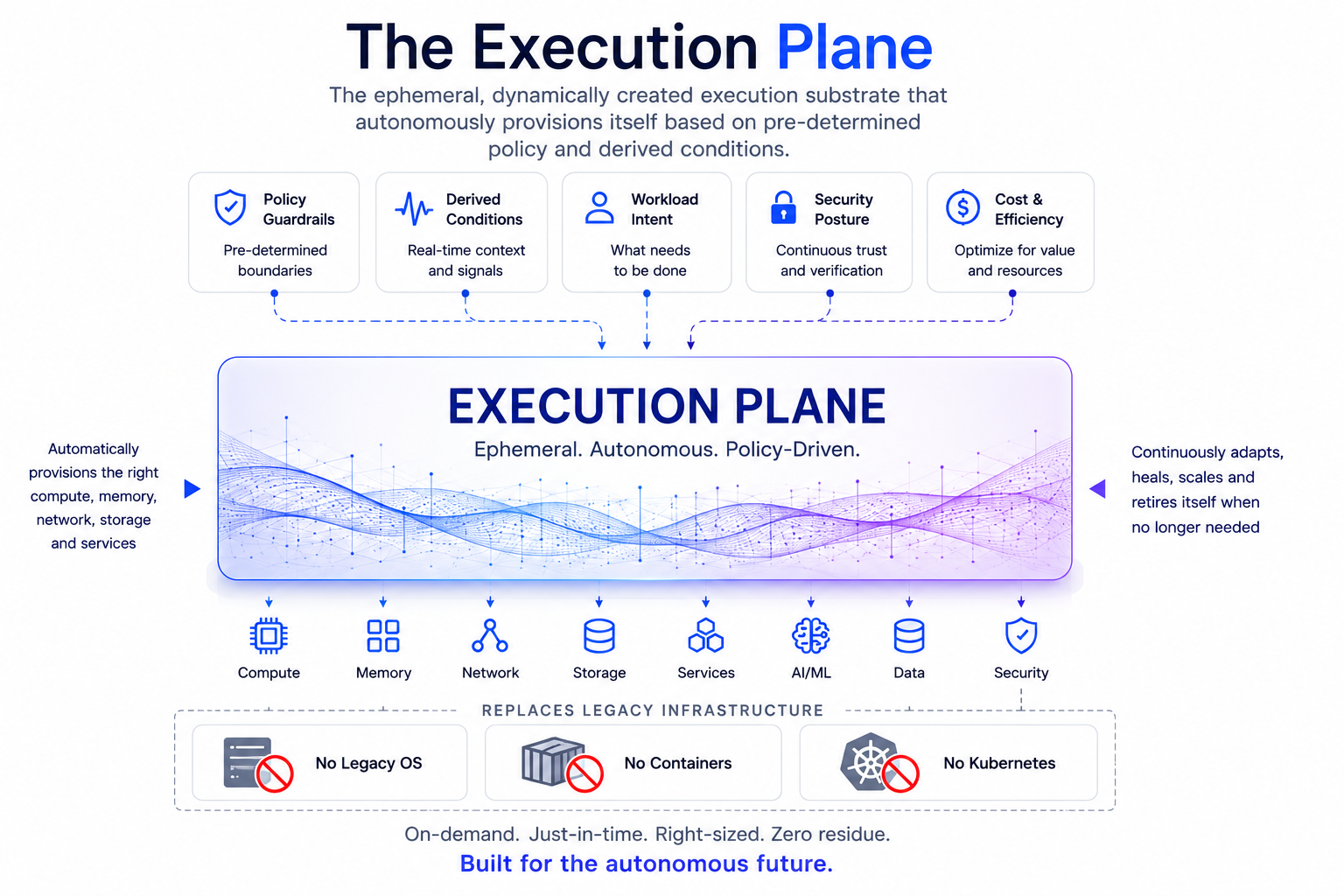
Execution Plane
Stateless Runtime Substrate (formerly zStation)
A Complete Re-Think
The Stateless Runtime Substrate for AI Inference and Learning
BeacenAI’s Execution Plane is the dynamically created execution substrate for AI-era infrastructure. It replaces the operational burden of legacy Linux, traditional container stacks, and Kubernetes-style orchestration with a stateless, policy-built runtime that constructs itself on demand, executes in memory, and disappears when the workload is complete.
For AI inference and learning workloads, this changes the economics of infrastructure. Instead of maintaining thousands of long-lived operating systems, patched images, container layers, runtime dependencies, node configurations, and recovery processes, BeacenAI regenerates the required execution environment from policy every time. The result is faster deployment, faster recovery, less human intervention, lower power consumption, reduced cooling demand, and lower water usage across large-scale AI infrastructure.
Built for AI Inference at Scale
AI inference requires enormous numbers of execution instances that must start quickly, run consistently, remain secure, and recover instantly. Traditional infrastructure was not designed for that level of operational velocity. Every server instance, operating system, container host, orchestration layer, patch cycle, configuration drift event, and failure recovery process adds friction.
The BeacenAI Execution Plane removes that friction. It creates only the runtime required for the workload, on the hardware available, under policy control. Inference workloads can be deployed as lightweight, deterministic execution environments rather than full legacy software stacks. This reduces startup time, lowers operational complexity, and allows infrastructure to scale without requiring proportional increases in administrators, DevOps teams, or manual remediation.
Accelerating AI Learning Workloads
AI learning and model-training environments are complex, dependency-heavy, and highly sensitive to configuration consistency. Driver versions, accelerator libraries, runtime components, network behavior, storage access, and workload policy all need to align. In conventional environments, those dependencies create fragile systems that must be maintained, patched, debugged, and rebuilt by human teams.
BeacenAI changes that model. The Execution Plane assembles the required learning environment from validated modules at runtime. The environment is not a snowflake server. It is not a manually maintained image. It is a policy-materialized execution layer that can be reproduced, updated, replaced, or regenerated automatically.
This allows AI learning infrastructure to be treated as disposable, repeatable, and self-recovering.
Lower Human Capital Requirements
Modern AI infrastructure is becoming too large and too dynamic to operate manually. The limiting factor is no longer just compute capacity. It is the human effort required to deploy, configure, secure, patch, monitor, repair, and recover the execution environments that run AI workloads.
BeacenAI reduces that dependency on human capital by eliminating many of the operational tasks that consume infrastructure teams today. There are no traditional imaging rituals, no long-lived operating system drift, no manual rebuild cycles, and no need to treat every node as a unique administrative object. If a node fails, deviates, or becomes untrusted, it is regenerated from policy.
This shifts operations from human-driven maintenance to autonomous regeneration.
Reduced Power, Cooling, and Water Demand
AI data centers are constrained by power and cooling. Water usage is increasingly tied directly to infrastructure efficiency. Every unnecessary software layer, idle service, bloated operating system, excessive rebuild process, and inefficient runtime consumes power and contributes to heat.
The Execution Plane is intentionally small, stateless, and workload-specific. By reducing the runtime footprint and removing unnecessary legacy layers, BeacenAI reduces the amount of software that must be loaded, maintained, secured, and kept alive. More efficient execution means less wasted compute, lower power demand, reduced cooling load, and lower water consumption in facilities that depend on water-based cooling systems.
For large AI factories, those savings compound across thousands or millions of execution instances.
Faster Deployment
Traditional deployment depends on prebuilt images, package management, container registries, orchestration logic, configuration tooling, persistent node state, and human-supervised troubleshooting. That approach slows down AI infrastructure at the exact moment AI workloads require extreme elasticity.
BeacenAI deploys by construction. The Control Plane defines the policy. The Execution Plane builds the runtime. Required modules are delivered, validated, fused, and executed dynamically. Only the components required for the workload and hardware are present.
Deployment becomes a policy-driven act of generation, not a manual act of installation.
Faster Recovery
Conventional systems recover by repair. BeacenAI recovers by regeneration.
When a traditional AI node fails, teams often need to diagnose, patch, rebuild, reimage, redeploy, or manually return the system to service. That process consumes time, people, power, and operational attention.
With BeacenAI, the Execution Plane is perishable by design. Failed or compromised environments do not need to be repaired. They can be discarded and rebuilt from known-good policy. This dramatically reduces recovery time and eliminates the operational uncertainty caused by persistent state, drift, and hidden configuration changes.
Stateless and Secure by Design
Every Execution Plane session is a clean instantiation of the required runtime. The base system is read-only, cryptographically validated, and executed in volatile memory. No durable operating system state is left behind. No uncontrolled software is allowed to persist. No workload environment is trusted simply because it existed before.
This model sharply reduces malware, ransomware, insider risk, and configuration drift. For AI workloads, it also protects the integrity of the execution environment supporting models, data pipelines, inference services, and learning systems.
The New Execution Layer for AI Infrastructure
The BeacenAI Execution Plane is not another operating system distribution, container platform, or Kubernetes replacement layer. It is a different operating model.
It provides a stateless, policy-built, autonomously regenerated execution substrate for AI inference, learning, edge, desktop, and server workloads. It reduces human capital requirements, improves deployment speed, accelerates recovery, lowers power and cooling demands, reduces water impact, and enables AI infrastructure to scale without being limited by legacy operational friction.
Bottom line: BeacenAI does not maintain infrastructure the old way. It regenerates the execution environment AI needs, when it needs it, where it needs it.
BeacenAI Platform Benefits
Execution From Policy
The Control Plane defines intent. The Execution Plane constructs the runtime. What exists at boot is what policy permits—nothing else.
Stateless by Design
Every session is a clean instantiation of the environment. No drift, no decay, no “snowflake” machines. The system is rebuilt each run—not maintained over time.
Security From Architecture
A read-only base plus cryptographic validation sharply reduces attack surface. Persistence-based compromise collapses when the OS and runtime cannot be written to.
Adaptive to Context
Device type, identity, and location determine what is constructed. One Execution Plane spans desktop, server, edge, and contested environments without branching stacks.
Deterministic Runtime
Modules are delivered, verified, and fused into a known-good image. The platform knows what should be running at every stage—because it assembled it.
Zero-Touch Operations
No imaging rituals. No manual rebuilds. No drift remediation loops. If a node fails or deviates, it is regenerated automatically from policy.